
Modern GenAI Application Architectures
How startup and enterprise GenAI architectures evolve across time horizon, frontier model capabilities, and Cloud

How are GenAI application architectures evolving in the enterprise and within startups? What are the building blocks? How do various moving parts fit in? How do cloud architectures interplay with GenAI? These are the key questions that I will be addressing in this article.

Let us start by grounding what a modern GenAI application architecture looks like.
A16z Emerging Architectures for LLM Applications is one of the best representations of the modern LLM app stack. The stack is optimized for frontier models which enable in-context learning or user instruction following with large conversational context to enable multi-turns as well as retrieval of large texts or embeddings within context. This architecture was published in June 2023 and has mostly stood the test of time in a rapidly evolving GenAI space.
Listen to an AI moderated podcast based on this article.
A16z notes that this reference architecture shows the most common systems, tools, and design patterns we’ve seen used by AI startups and sophisticated tech companies.
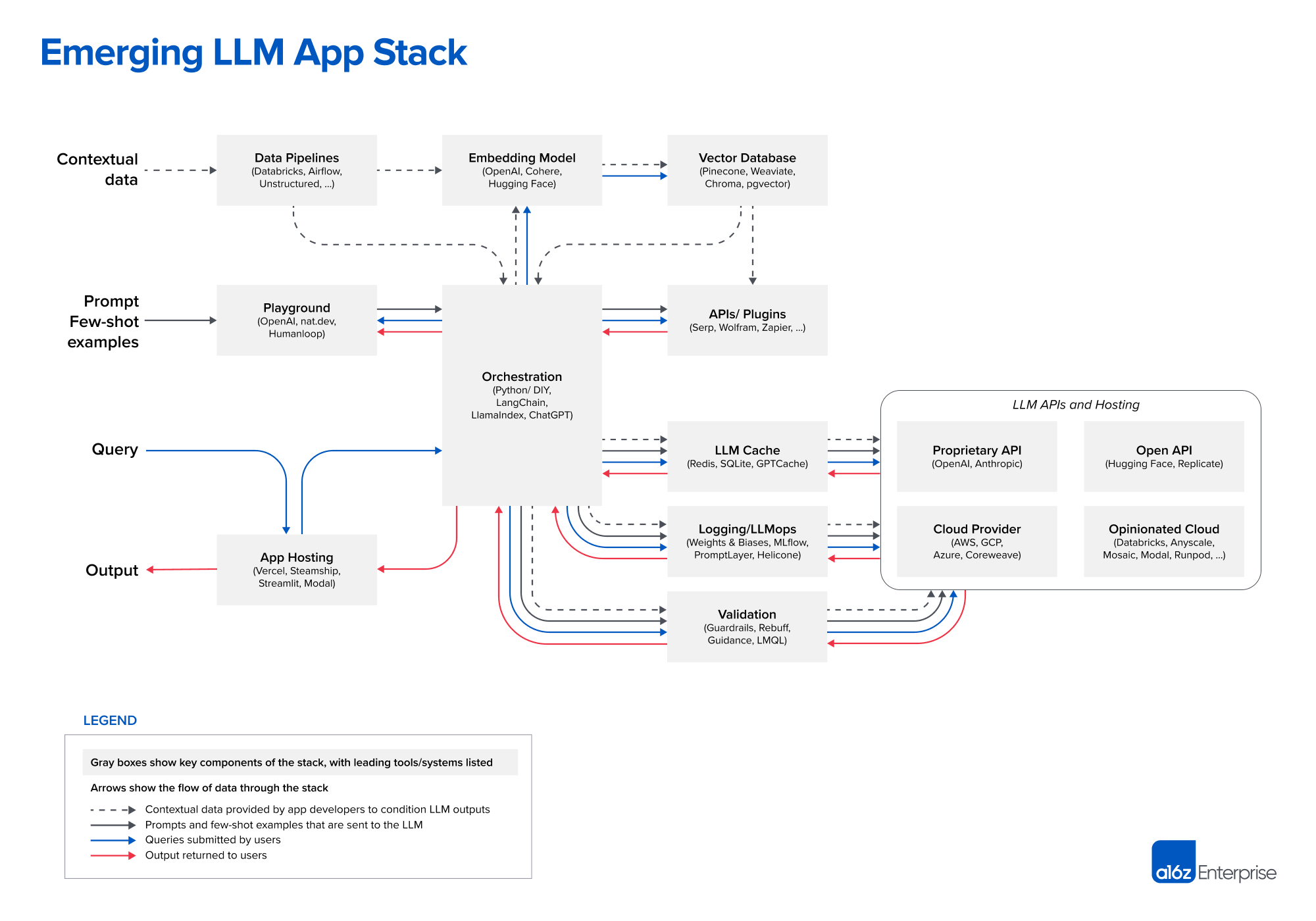
Stack Evolution Within 14 Months
A16z tracks the evolving stack of tools in the live GitHub repo here. Comparing the 2023 and 2024 versions of the stack yield several interesting insights.
Overview of Changes: The a16z LLM stack has grown substantially from 2023 to 2024. The 2023 stack contained approximately 30 providers across 12 categories, while the 2024 version includes over 70 providers across 14 categories.
Significant expansion
Data Pipelines: The category doubled in size, adding Fivetran, Airbyte, and Alluxio to the existing providers. These additions focus primarily on enterprise data integration and preprocessing capabilities.
Vector Databases: The vector database category expanded from 4 providers in 2023 to 8 in 2024, adding Zilliz (Milvus), Qdrant, Metal.io, and LanceDB. This growth reflects increasing demand for specialized vector storage solutions at different scales.
Monitoring and Evaluation: The most substantial growth occurred in monitoring tools, expanding from 4 providers in 2023 to over 15 in 2024. New entrants include Braintrust Data, Arize AI, Quotient AI, and several others focusing on specific aspects of LLM deployment monitoring and evaluation.
Key market trends
Enterprise Integration: The 2024 stack shows increased emphasis on enterprise-grade solutions, particularly in data pipelines and monitoring. Tools now commonly feature enterprise-specific capabilities like SSO, compliance monitoring, and integration with existing data infrastructure.
Specialized Solutions: While the 2023 stack featured mostly general-purpose tools, the 2024 version includes more specialized solutions. For example, the vector database category now includes options optimized for specific use cases like high-throughput scenarios or edge deployment.
Open Source Growth: The proportion of open-source solutions has increased, particularly in the vector database and validation categories. This trend provides organizations with more flexibility in deployment and customization options.
More mature technical infrastructure
Monitoring and Observability: The significant expansion in monitoring tools indicates that organizations are moving beyond basic implementation to focus on operational excellence. New tools provide capabilities for evaluation, performance monitoring, and continuous improvement.
Security and Validation: The addition of dedicated validation tools like LLM Guard and Outlines, along with expanded security features across other categories, indicates increasing focus on production security requirements.
Infrastructure Integration: The 2024 stack demonstrates better integration with existing enterprise infrastructure, particularly in data pipelines and monitoring tools. This integration indicates that LLM technology is increasingly being viewed as a component of larger enterprise systems rather than a standalone capability.
Looking Forward: The stack's evolution from 2023 to 2024 shows clear signs of market maturation. Organizations now have access to more specialized tools, better monitoring capabilities, and more robust security options. This progression suggests continued expansion in enterprise-focused solutions and operational tools.
Frontier Model Capabilities Diverge Architecture
The A16z stack also diverges and evolves based on which frontier models are used and what tools are part of the stack.
Based on the recent innovations in frontier models there are some ways to extend this stack to leverage new model capabilities. One such capability is Anthropic Claude Computer Use which can interact with tools (or perform function calling) to manipulate a user computer desktop environment. This could extend the stack with Robotic Process Automation tools like UiPath as well as specialized UI testing automation tools like Selenium. This may also evolve security and sandbox tools which protect the user computer from unintended computer use by an LLM.
We can even collapse this stack in places where frontier models deliver parts of stack on their own. One such recently launched capability is reasoning or system 2 thinking with OpenAI o1 model release. This collapses parts of orchestration using capabilities like chain of thought provided by external tooling like LangChain, instead enabled by the frontier model itself. Retrieval or vector database is another area which can be collapsed with OpenAI Assistants API capability to use File Search tool.
OpenAI Advancements
GPT-4 Turbo: 128K context window, Knowledge cutoff: April 2024, Improved JSON mode reliability, Enhanced function calling
GPT-4V (Vision): Advanced image understanding, Detail-oriented image analysis, Multi-image comparison capabilities
Assistant API Improvements: Code interpreter, Retrieval without vector DBs, File management capabilities
Anthropic Innovations
Claude 3 Family: Sonnet: Enhanced reasoning, Opus: Complex task handling, Haiku: Fast response optimization
Tool Use Capabilities: Direct computer interaction, File system navigation, Application control
Constitutional AI Improvements: Enhanced safety boundaries, Better task refusal handling, Improved ethical reasoning
Meta's Contributions
Llama 3: Improved open-source performance, Enhanced multilingual capabilities, Better context handling
Code Llama: Specialized code generation, Multiple programming language support, Improved documentation generation
Google's Developments
Gemini Ultra: Advanced multimodal capabilities, Enhanced reasoning, Improved factual accuracy
Gemini Pro: Cost-effective deployment, Balanced performance, Enterprise integration focus
Architectural Implications
These advancements suggest several architectural shifts:
Reduced Infrastructure Requirements:
Native retrieval capabilities reducing vector DB dependency
Built-in tool use minimizing orchestration needs
Enhanced JSON mode improving integration reliability
Security Architecture Evolution:
Computer use capabilities requiring new sandbox approaches
Enhanced content filtering at model level
Tool use permission management
Simplified RAG Patterns:
Model-native retrieval capabilities
Improved context handling reducing chunking complexity
Better multimodal understanding enabling diverse data sources
Development Workflow Changes:
Enhanced code generation capabilities
Improved documentation automation
Better test generation support
Mapping Thoughtworks Radar With A16z
Thoughtworks Technology Radar is a twice-yearly snapshot of tools, techniques, platforms, languages and frameworks. This knowledge-sharing tool is based on their global teams’ experience. It categorizes technologies into four dimensions.
Adopt. Technologies that you should seriously consider using.
Trial. Technologies that are ready for use, but not as completely proven as those in the Adopt ring.
Assess. Technologies to look at closely, but not necessarily trial yet — unless you think they would be a particularly good fit for you.
Hold. Proceed with caution.
Foundation Models & APIs
FastChat (Trial) - Open platform for training, serving, and evaluating LLMs
vLLM (Trial) - High-throughput, memory-efficient inference engine
LiteLLM (Trial) - Unified interface for multiple LLM providers
Small language models (Trial) - Lightweight alternatives to large models
On-device LLM inference (Assess) - Browser and edge device model deployment
Development & Orchestration
Function calling with LLMs (Trial) - Integration with external functions and APIs
LLM-powered autonomous agents (Assess) - Complex task automation
Microsoft Autogen (Assess) - Multi-agent collaboration framework
LLM Guardrails (Trial) - Safety and control frameworks
Instructor (Trial) - Structured output handling
DSPy (Assess) - Higher-level LLM programming abstractions
Retrieval & Embeddings
Retrieval-augmented generation (RAG) (Adopt) - Core pattern for improved response quality
Fine-tuning embedding models (Trial) - Domain-specific embedding optimization
Qdrant (Trial) - Vector similarity search engine
Vespa (Trial) - Search and big data processing platform
pgvector (Trial) - PostgreSQL vector similarity extension
Azure AI Search (Assess) - Cloud-based vector search service
ColPali (Assess) - PDF document retrieval using vision language models
Monitoring & Evaluation
Langfuse (Trial) - Observability and evaluation platform
Observability 2.0 (Assess) - Unified monitoring approach
DeepEval (Assess) - LLM performance evaluation framework
Ragas (Assess) - RAG pipeline evaluation
LLMLingua (Assess) - Prompt optimization and compression
Data Processing & Storage
Databricks Unity Catalog (Trial) - Data governance solution
Databricks Asset Bundles (Trial) - Asset packaging and deployment
Kedro (Trial) - MLOps framework
dbldatagen (Assess) - Synthetic data generation
Data Mesh Manager (Assess) - Metadata management platform
Developer Tools & Experience
AI team assistants (Assess) - Team collaboration tools
Cursor (Assess) - AI-first code editor
JetBrains AI Assistant (Assess) - IDE integration
GitButler (Assess) - Git client with AI features
Unblocked (Assess) - SDLC asset discovery platform
Security & Compliance
LLM Guardrails (Trial) - Safety constraints and filtering
Wiz (Adopt) - Cloud security platform
AWS Control Tower (Trial) - Governance and compliance controls
Dynamic few-shot prompting (Assess) - Context-aware prompt security
Structured output from LLMs (Assess) - Controlled response formatting
Notable Anti-patterns & Cautions
Complacency with AI-generated code (Hold) - Over-reliance on AI suggestions
Replacing pair programming with AI (Hold) - Loss of human collaboration benefits
LLM bans (Hold) - Counterproductive restriction policies
Enterprise-wide integration test environments (Hold) - Testing bottlenecks
Best Practices & Recommendations
Implement comprehensive monitoring and evaluation frameworks
Use RAG patterns for improved response quality and reduced hallucinations
Consider small language models for specific use cases
Maintain strong engineering practices alongside AI adoption
Focus on team collaboration rather than individual AI assistance
Implement proper guardrails and security measures
Use synthetic data for testing when appropriate
Leverage structured outputs for better control and integration
This mapping shows how the Thoughtworks Radar complements and extends the A16z stack with additional tools, frameworks, and practices that enhance each component of the LLM application architecture. The combination provides a more complete picture of the current state of LLM application development and deployment.
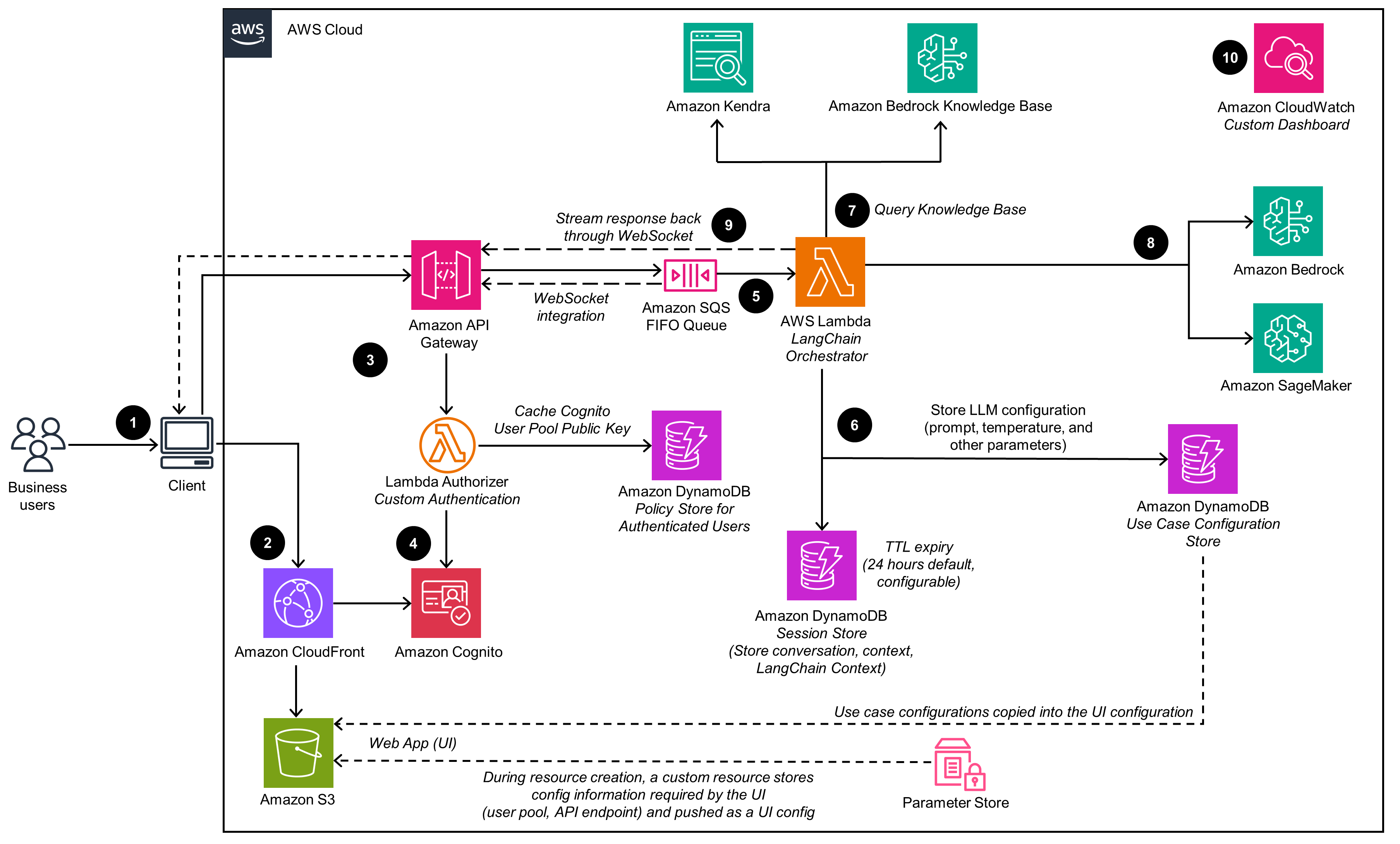
AWS Reference Architecture
AWS provides reference implementation architecture for text GenAI use case enabled over AWS Cloud. This architecture uses AWS Serverless Compute which means we do not need to worry about managing compute or scaling. Note how AWS Serverless architecture has fewer moving parts than A16z architecture, yet it matches the A16z architecture in several ways. Just three AWS services, Amazon Bedrock, AWS Lambda, and Amazon DynamoDB enable large part of the LLM architecture.
The orchestration employs LangChain. The LangChain Orchestrator is a collection of Lambda functions that provide the business logic for fulfilling user requests. The playground is enabled by Amazon Bedrock for chat, text, and vision models. The LLM API and hosting as well as the Embedding Model is also provisioned by Amazon Bedrock. Bedrock also provides Validation via guardrails. Logging is enabled by Amazon CloudWatch. Retrieval Data Pipelines are enabled by Amazon Bedrock Knowledge Base.
AWS reference architecture adds a Session Store via Amazon DynamoDB. LLM Cache can be enabled by extending this architecture with Amazon DynamoDB Accelerator (DAX) an in-memory cloud cache that is API-compatible with DynamoDB. We can also extend this architecture to add a Vector Store via Amazon OpenSearch Service.
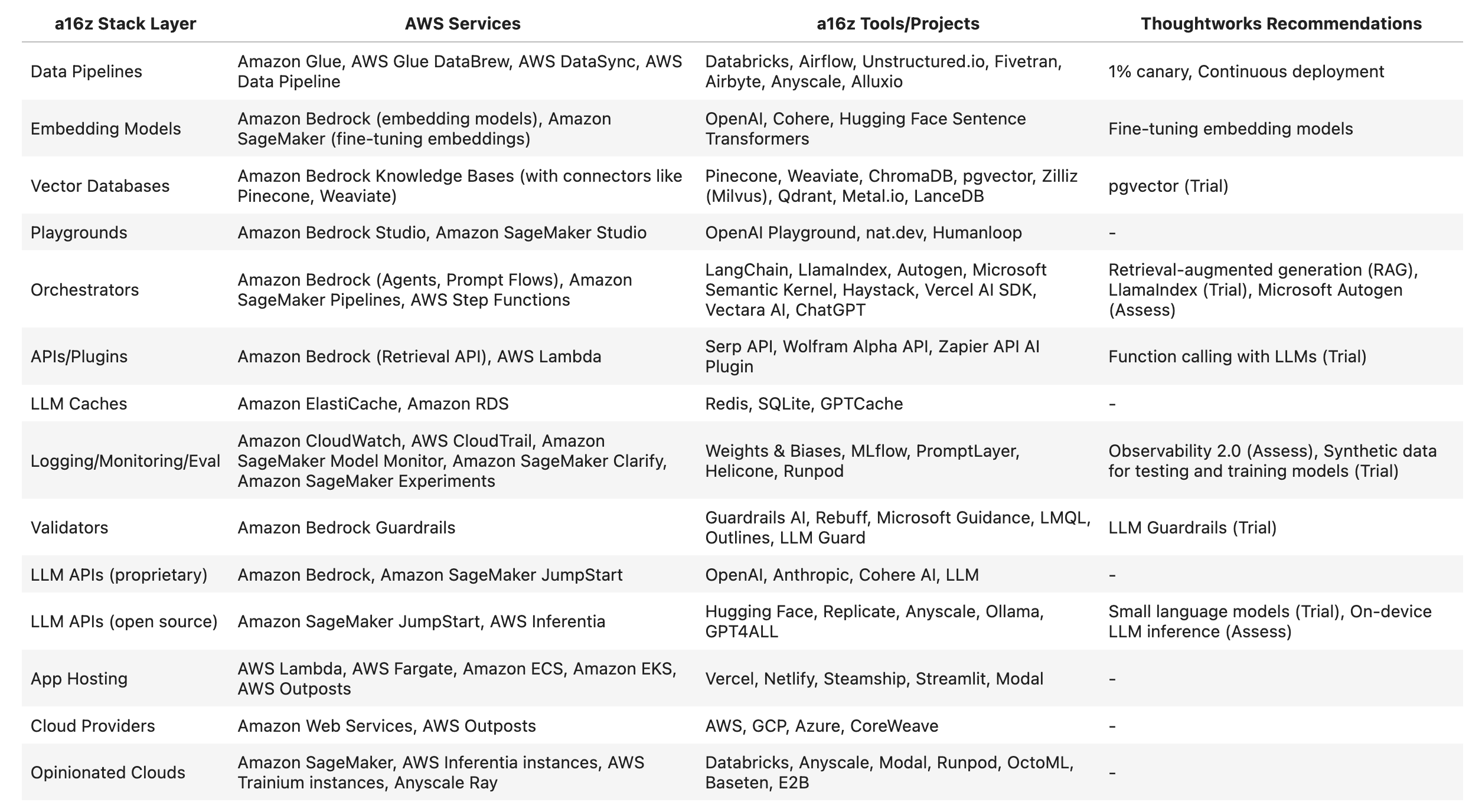
AWS AI Services Aligning A16z and Thoughtworks Recommendations
AWS offers a comprehensive suite of AI services that not only map to the A16z stack components but also extend beyond them. Here's how AWS services align with and expand the reference architecture while following the ThoughtWorks recommendations:
Foundation Models & APIs
SageMaker JumpStart supports Thoughtworks' trial recommendation for small language models
Amazon Bedrock: Primary service for accessing foundation models from Amazon, Anthropic, AI21 Labs, Cohere, and Stability AI.
Amazon SageMaker JumpStart: Provides access to open-source models and fine-tuning capabilities.
Amazon Titan: AWS's proprietary family of foundation models including:
Titan Text - for text generation and embedding
Titan Image - for image generation
Titan Multimodal - for image understanding and text generation
Vector Databases & Retrieval
Follows Thoughtworks' adopt recommendation for RAG patterns
Amazon OpenSearch Service: Managed service supporting vector search with k-NN
Amazon OpenSearch Serverless: Serverless vector search option
Amazon Neptune ML: Graph database with vector search capabilities
Amazon Aurora ML: Vector search capabilities integrated into PostgreSQL
Data Processing & Pipelines
Aligns with Thoughtworks' trial status for Databricks tools
Amazon EMR: Processing large-scale data for AI/ML workloads
AWS Glue: ETL service for data preparation
Amazon Kinesis: Real-time data streaming and processing
AWS Data Pipeline: Orchestration service for data-driven workflows
Amazon SageMaker Data Wrangler: Visual interface for data preparation
Orchestration & Development
Supports Thoughtworks' trial recommendation for function calling with LLMs
AWS Step Functions: Workflow orchestration with built-in ML steps
Amazon SageMaker Pipelines: ML-specific workflow orchestration
AWS Lambda: Serverless compute for model inference and orchestration
Amazon ECS/EKS: Container orchestration for ML workloads
AWS Fargate: Serverless container compute
Monitoring & Observability
Maps to Thoughtworks' trial recommendation for Langfuse
Amazon CloudWatch: Comprehensive monitoring and logging
AWS CloudTrail: API activity and usage tracking
Amazon SageMaker Model Monitor: ML-specific monitoring including:
Data quality monitoring
Model quality monitoring
Bias drift monitoring
Feature attribution drift monitoring
Amazon SageMaker Clarify: Bias detection and model explainability
Security & Governance
Supports LLM Guardrails implementation
AWS IAM: Fine-grained access control
Amazon Macie: Sensitive data discovery and protection
AWS KMS: Key management for model and data encryption
Amazon SageMaker Model Cards: Model governance and documentation
AWS CloudFormation Guard: Policy as code for AI/ML resources
Storage & Caching
Amazon S3: Object storage for models and data
Amazon DynamoDB: NoSQL database with DAX caching
Amazon ElastiCache: In-memory caching
Amazon FSx: High-performance file systems
AI-Specific Features That Extend Beyond A16z Stack
Computer Vision Services
Amazon Rekognition: Pre-trained computer vision
Amazon Lookout for Vision: Industrial anomaly detection
Amazon Textract: Document text extraction
Speech & Audio Services
Amazon Transcribe: Speech-to-text
Amazon Polly: Text-to-speech
Amazon Kendra: Enterprise search with natural language understanding
Specialized AI Tools
Amazon CodeWhisperer: AI-powered code generation
Amazon HealthLake: Healthcare-specific AI services
Amazon Fraud Detector: AI-powered fraud detection
Amazon Personalize: AI-powered personalization service
Enterprise Integration Advantages
AWS's AI services offer several advantages for enterprise integration:
Unified Security Model: All services integrate with AWS IAM, providing consistent security controls
Cost Optimization: Pay-as-you-go pricing with ability to reserve capacity
Regulatory Compliance: Services are compliant with major standards (HIPAA, SOC, ISO, etc.)
Global Availability: Services available across multiple regions
Enterprise Support: Access to AWS Enterprise Support with ML specialists
Architectural Benefits
The AWS AI services ecosystem provides several architectural advantages:
Reduced Complexity: Fewer integration points compared to multi-vendor solutions
Serverless Options: Many services offer serverless variants reducing operational overhead
Built-in High Availability: Services are designed for enterprise-grade availability
Automatic Scaling: Most services handle scaling automatically
Cross-Service Integration: Native integration between services reduces development effort
This comprehensive suite of AWS AI services not only matches the components in the A16z stack but extends it with additional capabilities specifically designed for enterprise use cases. AWS best practices align with Thoughtworks recommendations as well. The tight integration between services and the ability to leverage existing AWS infrastructure makes it particularly attractive for organizations already invested in the AWS ecosystem.