
Modern LLM Development Workflows: A Comprehensive Guide
Comparing how frontier models are built and how breakthrough student models like DeepSeek are built based on frontier models

This guide explores the key steps and techniques in developing state-of-the-art Language Learning Models (LLMs), drawing from recent advances in the field. The guide is divided into two sections. First section explores how frontier models are built. Second section elaborates how student models are built based on frontier models.
The article also covers recent innovations in training the DeepSeek model which has delivered breakthrough performance (top 3 rankings on LLM leaderboards) at a fraction of training cost of leading frontier models.

Listen to AI moderated podcast based on this article
Frontier Model Development
Large Language Models (LLMs) have revolutionized AI, but their development follows a complex workflow. Let's explore each stage of this process, from data collection to deployment.
Data Collection
The foundation of any LLM begins with massive text datasets. Leading models like LLaMA, GPT-3, and Claude rely on web crawling techniques using tools like CommonCrawl and C4. This process involves extensive quality filtering and deduplication to ensure data integrity. According to the LLaMA Paper, careful data curation significantly impacts model performance.
Data Preprocessing
Text data must be converted into a format that models can process. This involves tokenization, typically using either byte-pair encoding (BPE) or SentencePiece. LLaMA, for instance, employs BPE with a 32,000-token vocabulary, as detailed in their technical documentation.
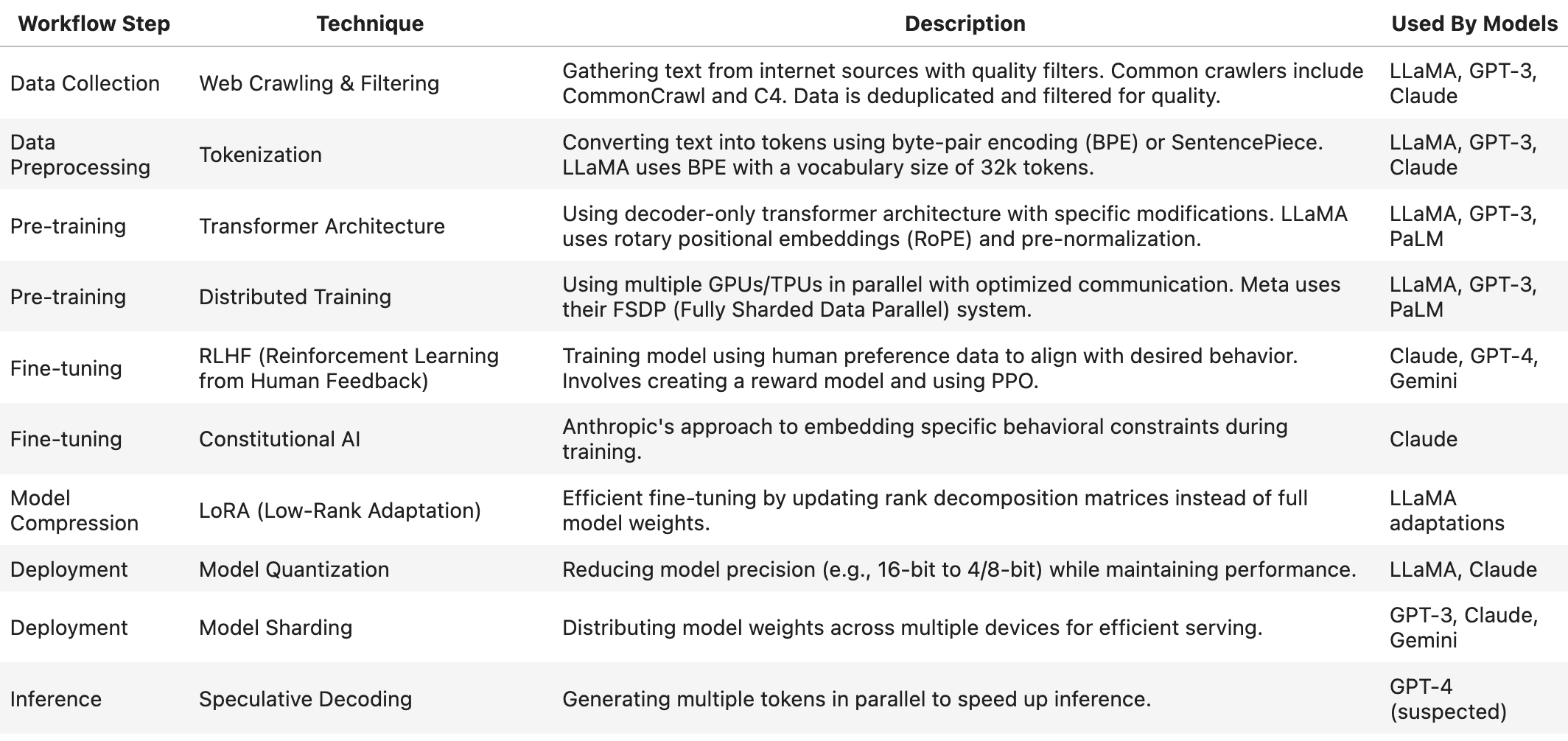
Pre-training Phase
Architecture
Modern LLMs primarily use decoder-only transformer architectures. LLaMA, GPT-3, and PaLM incorporate specific enhancements like rotary positional embeddings (RoPE) and pre-normalization to improve performance.
Distributed Training
Training these massive models requires sophisticated distributed computing approaches. Meta's FSDP (Fully Sharded Data Parallel) system, detailed in their engineering blog, enables efficient training across multiple GPUs/TPUs.
Fine-tuning Approaches
RLHF
Reinforcement Learning from Human Feedback (RLHF) has become crucial for aligning models with human preferences. Models like Claude, GPT-4, and Gemini use RLHF to improve their outputs' quality and safety. This involves creating reward models and implementing Proximal Policy Optimization (PPO).
Constitutional AI
Anthropic pioneered Constitutional AI, a specialized approach to embedding behavioral constraints during training. This technique, detailed in their research paper, is fundamental to Claude's development.
Model Optimization
Compression Techniques
LoRA (Low-Rank Adaptation), described in the original paper, enables efficient fine-tuning by updating rank decomposition matrices instead of full model weights. This has been particularly successful with LLaMA adaptations.
Deployment Strategies
Quantization
Model quantization reduces precision (e.g., from 16-bit to 4/8-bit) while maintaining performance. This technique is crucial for deploying large models like LLaMA and Claude efficiently.
Model Sharding
Distributing model weights across multiple devices is essential for serving large models. GPT-3, Claude, and Gemini use sophisticated sharding techniques, with tools like Microsoft DeepSpeed leading the way.
Inference Optimization
Speculative decoding, detailed in this research paper, allows for parallel token generation to speed up inference. While not officially confirmed, it's believed that GPT-4 employs this technique.
Important Notes
Many implementation details for commercial models remain proprietary
These techniques often overlap and may be used concurrently
The field evolves rapidly, with new optimizations emerging regularly
Not all techniques used by commercial models are publicly documented
This workflow represents the current state-of-the-art in LLM development, though the landscape continues to evolve with new research and innovations.
Student Model Development
Base Model Selection
The foundation of any LLM development starts with selecting an appropriate base model. Leading organizations like DeepSeek, Yi, and Nemotron typically choose larger foundation models as teachers, such as LLaMA. The teacher model is usually 2-3 times larger than the target student model, as detailed in the DeepSeek Technical Report.
Data Preparation and Pre-training
High-quality training data is crucial for model performance. Modern approaches use a carefully curated mixture of data sources:
30% web content
30% books
20% code
20% academic papers and research
This distribution, as documented in the Yi Paper, has proven effective across multiple successful models including DeepSeek, Yi, and Nemotron.
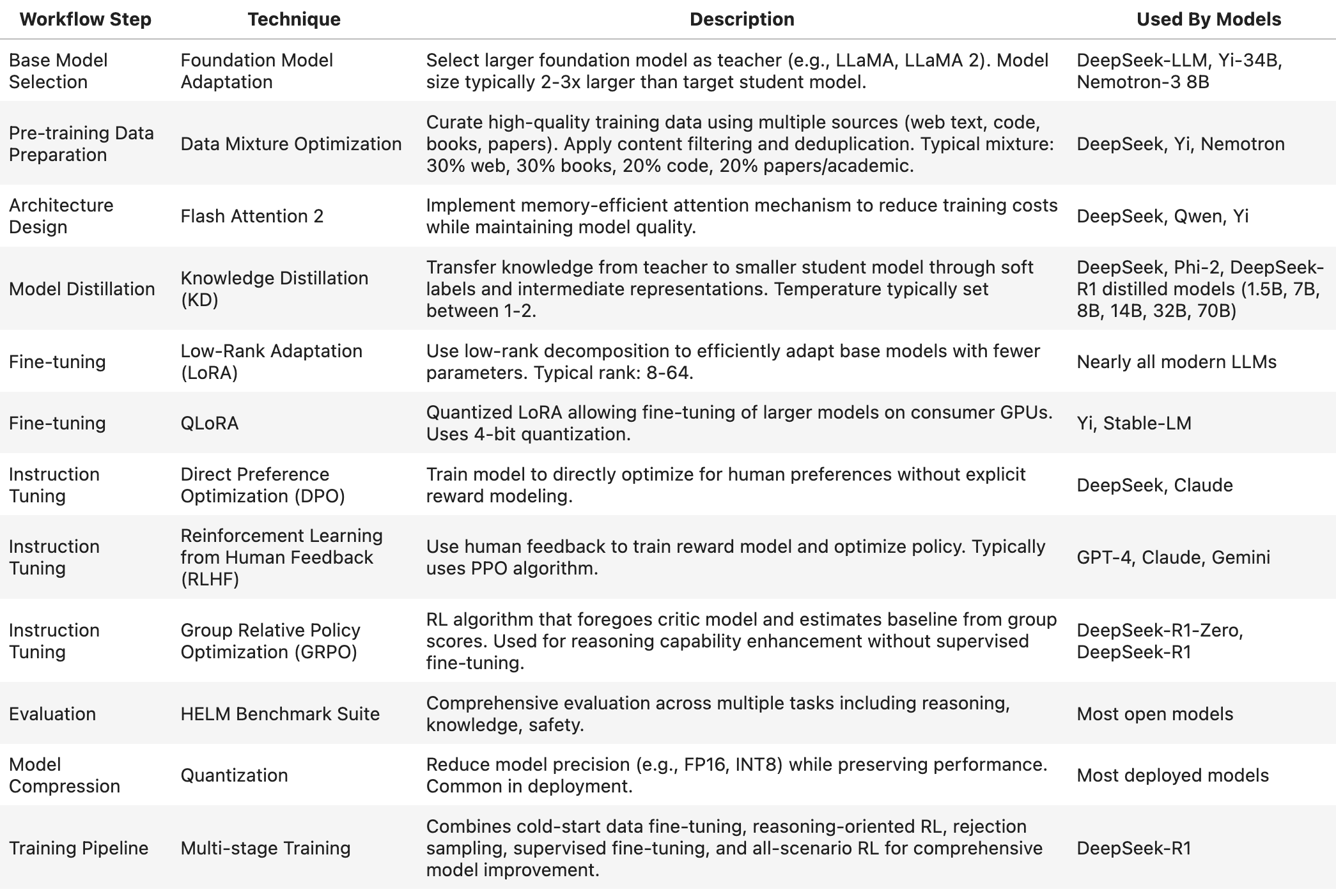
Architecture Optimization
Memory efficiency is a key consideration in model architecture. Many leading models, including DeepSeek, Qwen, and Yi, implement FlashAttention-2, a memory-efficient attention mechanism that reduces training costs while maintaining model quality.
Knowledge Transfer and Model Distillation
Knowledge Distillation (KD) enables the transfer of knowledge from larger teacher models to smaller student models. This technique has been successfully employed by:
DeepSeek's R1 family (1.5B, 7B, 8B, 14B, 32B, 70B models)
Microsoft's Phi-2
Temperature settings typically range between 1-2 during the distillation process. For more details, see the Microsoft Phi-2 Blog and DeepSeek Paper.
Fine-tuning Approaches
Two prominent fine-tuning methods have emerged:
Low-Rank Adaptation (LoRA): This efficient adaptation technique uses low-rank decomposition, typically with ranks between 8-64. It's become nearly universal among modern LLMs. Learn more in the LoRA Paper.
QLoRA: This quantized version of LoRA enables fine-tuning of larger models on consumer GPUs using 4-bit quantization, as implemented by Yi and Stable-LM. Details in the QLoRA Paper.
Instruction Tuning Methods
Three main approaches dominate instruction tuning:
Direct Preference Optimization (DPO): Used by DeepSeek and Claude, this method optimizes for human preferences without explicit reward modeling. See the DPO Paper.
Reinforcement Learning from Human Feedback (RLHF): Implemented by GPT-4, Claude, and Gemini, this approach uses human feedback to train reward models and optimize policies, typically using the PPO algorithm. More details in Anthropic's RLHF Blog.
Group Relative Policy Optimization (GRPO): DeepSeek's innovation that enhances reasoning capabilities without supervised fine-tuning by estimating baselines from group scores, eliminating the need for a critic model.
Evaluation and Deployment
Models are typically evaluated using the comprehensive HELM Benchmark Suite, which tests reasoning, knowledge, and safety capabilities.
For deployment, most models undergo quantization to reduce precision (e.g., FP16, INT8) while maintaining performance. The GPTQ Paper provides detailed insights into this process.
Advanced Training Pipeline
The AI research team at DeepSeek has made a remarkable breakthrough in language model training with their latest model, DeepSeek-R1. What makes this development particularly fascinating is their novel approach to enhancing AI reasoning capabilities through reinforcement learning (RL).
The Zero-to-Hero Story: DeepSeek-R1-Zero
Perhaps the most intriguing aspect of this research is DeepSeek-R1-Zero, a model trained purely through reinforcement learning without any supervised fine-tuning. This "blank slate" approach yielded surprising results - the model naturally developed sophisticated reasoning behaviors and achieved impressive performance metrics. For instance, it reached a 71% accuracy rate on the challenging AIME 2024 mathematics exam, jumping from an initial 15.6%.
What's particularly fascinating is how the model developed an "aha moment" during training - learning to pause, reflect, and reconsider its approach to problems, much like a human would. This emerged naturally from the reinforcement learning process, without being explicitly programmed.
The Refined Approach: DeepSeek-R1
While DeepSeek-R1-Zero showed promising results, it had some limitations in readability and language consistency. This led to the development of DeepSeek-R1, which implements a more sophisticated multi-stage training pipeline:
Cold Start: The process begins with fine-tuning using thousands of carefully curated examples
Reasoning-focused RL: Applying reinforcement learning specifically targeted at reasoning tasks
Rejection Sampling: Creating new training data by filtering the best outputs from the RL checkpoint
Supervised Fine-tuning: Combining reasoning data with general capabilities like writing and factual QA
Final RL Phase: A final round of reinforcement learning covering all usage scenarios
Impressive Results
The results speak for themselves. DeepSeek-R1 achieves remarkable performance across various benchmarks:
79.8% accuracy on AIME 2024 (matching OpenAI's o1-1217)
97.3% on MATH-500
96.3 percentile rating on Codeforces (competitive programming)
90.8% on MMLU (general knowledge)
Comparing DeepSeek and o1
Here is a side by side comparison on LMArena for DeepSeek and OpenAI o1 responses to the same prompt to generate code which clones VS Code or Cursor editor. The results speak for themselves.
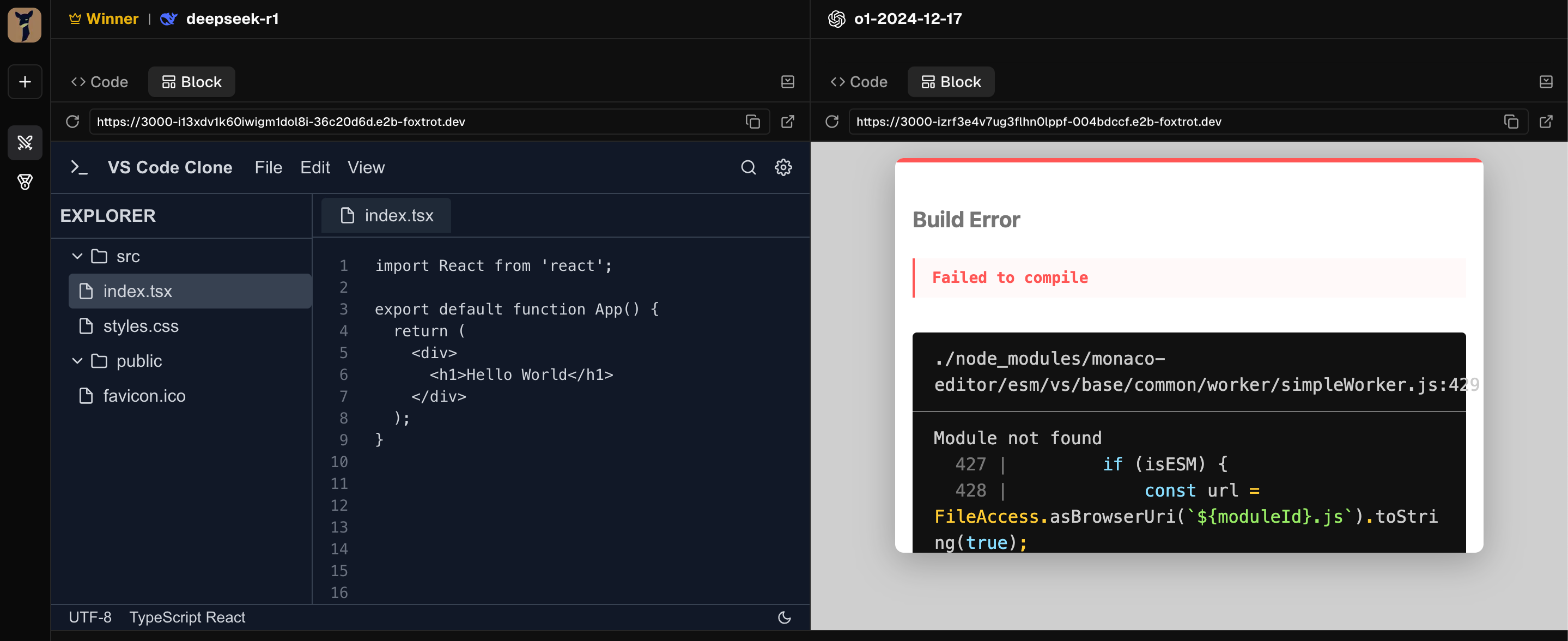
I tried multiple prompts including generating a Chess app and a Gmail app clone. DeepSeek won hands down compared to o1.
Democratizing Advanced Reasoning
One of the most promising aspects of this research is the successful distillation of these capabilities into smaller models. The team managed to create efficient versions ranging from 1.5B to 70B parameters, making advanced reasoning capabilities more accessible to researchers and developers with limited computational resources.
Looking Forward
While DeepSeek-R1 represents a significant advancement, the team acknowledges several areas for improvement, including:
Enhancing general capabilities like function calling and multi-turn interactions
Addressing language mixing issues in non-English/Chinese contexts
Improving performance on software engineering tasks
Reducing sensitivity to prompt formatting
This work opens up exciting new possibilities for developing AI systems with stronger reasoning capabilities, and the open-source nature of many of these models ensures that the broader research community can build upon these advances.
The success of DeepSeek-R1 demonstrates that reinforcement learning, when properly implemented, can be a powerful tool for developing more capable AI systems - particularly in areas requiring complex reasoning and problem-solving abilities.
This comprehensive approach, detailed in the DeepSeek Paper, represents the current state-of-the-art in LLM development pipelines.
Want to build your own advanced tuned model like DeepSeek? I will do a series of posts on how to do just that using the AWS Cloud. Please like, share, and subscribe.